Windows系统:Windows 10 家庭版
VMware版本:VMware®WorkSstation 15 Pro
Linux系统:Centos 7 64位最小化安装
本文章中以及笔者只使用三台机器
首先要明白高可用的含义:高可用、高可用性
按照本文来的话说白了就是两台namenode主机,一台宕机了另一台能补上就是高可用,两台机器也能搭建一个高可用,三台也能,五台也能,一万一亿台都能搭建,高可用的含义不是在于有多少台机器,而是在于几台namenode主机在有一台宕机了(停止工作了),另一台能接替宕机的岗位。通通俗易懂就是“换班”。
主机ip
|
主机名
|
安装软件
|
进程
|
192.168.1.4
|
Master1
|
jdk,hadoop,zookeeper
|
namenode, ZKFC,zookeeper,Journalnode,
|
192.168.1.10
|
Master2
|
jdk,hadoop,zookeeper
|
namenode, ZKFC,zookeeper,Journalnode,
|
192.168.1.11
|
Slave1
|
jdk,hadoop,zookeeper
|
datanode,zookeeper,Journalnode,
|
192.168.1.12
|
Slave2
|
jdk,hadoop,zookeeper
|
datanode,zookeeper,Journalnode,
|
192.168.1.13
|
Slave3
|
jdk,hadoop,zookeeper
|
datanode,zookeeper,Journalnode,
|
关闭防火墙:systemctl stop firewalld.service
安装jdk,zookeeper,Hadoop
记住自己的路径。
vim /etc/profile
环境示例:
#JAVA_HOME
export JAVA_HOME=/usr/apps/java/jdk
export PATH=$PATH:$JAVA_HOME/bin
#ZOOKEEPER_HOME
export ZOOKEEPER_HOME=/usr/apps/zookeeper/zookeeper-3.4.10
export PATH=$PATH:$ZOOKEEPER_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/usr/apps/hadoop/hadoop-2.7.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
翻译:
#JAVA_HOME
export JAVA_HOME=/usr/apps/java/jdk#JDK解压目录,我将jdk1.1.56什么版本啊什么的改成了jdk,方便记忆,可不更改。
export PATH=$PATH:$JAVA_HOME/bin#无需变更
#ZOOKEEPER_HOME
export ZOOKEEPER_HOME=/usr/apps/zookeeper/zookeeper-3.4.10#zookeeper解压目录
export PATH=$PATH:$ZOOKEEPER_HOME/bin#无需变更
#HADOOP_HOME
export HADOOP_HOME=/usr/apps/hadoop/hadoop-2.7.4#Hadoop解压目录
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin#无需变更
vim /etc/hosts
主机IP master1
主机IP master2
主机IP slave1
三台机器改名:hostnamectl set-hostname 主机名称(master1)/hostname 主机名称(master1)
发送刚配置好的hosts文件:scp /etc/hosts root@master2:/etc/ | scp /etc/hosts root@slave1:/etc/
笔者注:scp -r 是在发送某文件夹或递归文件夹时使用的命令,普通文件亦可使用。如:scp -r /usr/apps root@slave1:/usr/(将/usr/apps下的所有文件(包括apps文件夹)发送到slave1的usr目录下)
配置免密:戳我查看配置免密步骤 、 戳我查看配置免密步骤 两个配置免密教程(之前文章看过应该已经会配免密了)这里不细说了
更改zookeeper的解压目录下的conf下的zoo.cfg文件:
[root@master ~]# cd /usr/apps/zookeeper/zookeeper-3.4.10/conf/
[root@master conf]# ls
configuration.xsl log4j.properties zoo_sample.cfg
发现没有zoo.cfg文件,cp命令复制一份(你也可以选择直接改名:mv):cp zoo_sample.cfg zoo.cfg | 改名:mv zoo_sample.cfg zoo.cfg
编辑zoo.cfg文件
文件如下注意标红文字:
#dataDir文件为你的zookeeperdata的文件夹,推荐在zookeeper文件夹下建立
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/usr/apps/zookeeper/data
dataLogDir=/usr/apps/zookeeper/log
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to “0” to disable auto purge feature
#autopurge.purgeInterval=1
server.1=master1:2888:3888
server.2=master2:2888:3888
server.3=slave1:2888:3888
在zookeeper下的data文件夹下新建myid:
vim /usr/apps/zookeeper/data/myid
master1主机输入1
master2主机输入2
slave1主机输入3
后期发送文件后改正。
配置Hadoop文件:
Hadoop配置文件在Hadoop的解压目录下/etc/hadoop里:
例如:
[root@master data]# cd /usr/apps/hadoop/hadoop-2.7.4/etc/hadoop/
[root@master hadoop]# ls
capacity-scheduler.xml httpfs-env.sh mapred-env.sh
configuration.xsl httpfs-log4j.properties mapred-queues.xml.template
container-executor.cfg httpfs-signature.secret mapred-site.xml
core-site.xml httpfs-site.xml mapred-site.xml.template
hadoop-env.cmd kms-acls.xml slaves
hadoop-env.sh kms-env.sh ssl-client.xml.example
hadoop-metrics2.properties kms-log4j.properties ssl-server.xml.example
hadoop-metrics.properties kms-site.xml yarn-env.cmd
hadoop-policy.xml log4j.properties yarn-env.sh
hdfs-site.xml mapred-env.cmd yarn-site.xml
进入后修改配置文件:
修改编辑hadoop-env.sh
1、编辑hadoop-env.sh
vim /usr/apps/hadoop/hadoop-2.7.4/etc/hadoop/hadoop-env.sh
2、修改JAVA_HOME路径
export JAVA_HOME=/usr/apps/java/jdk
配置yarn-env.sh:
1、编辑hadoop-env.sh
vim /usr/apps/hadoop/hadoop-2.7.4/etc/hadoop/yarn-env.sh
2、修改JAVA_HOME路径
export JAVA_HOME=/usr/apps/java/jdk
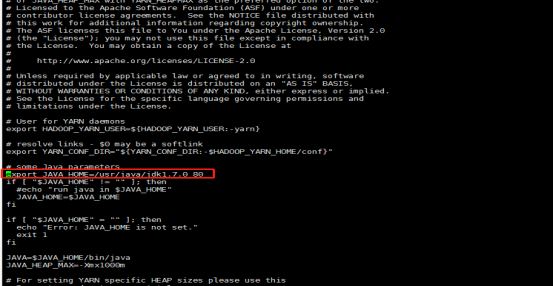
配置core-site.xml文件(没有tmp文件夹就新建tmp为hadoopdata目录)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/apps/hadoop/tmp</value>
<description>Abasefor other temporarydirectories.</description>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>master1:2181,master2:2181,slave1:2181,slave2:2181,slave3:2181</value>
</property>
</configuration>
配置hdfs-site.xml文件
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>cluster1</value>
</property>
<property>
<name>dfs.ha.namenodes.cluster1</name>
<value>master1,master2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster1.master1</name>
<value>master1:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster1.master1</name>
<value>master1:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster1.master2</name>
<value>master2:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster1.master2</name>
<value>master2:50070</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.cluster.master1</name>
<value>master1:53310</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.cluster.master2</name>
<value>master2:53310</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled.cluster1</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master1:8485;master2:8485;slave1:8485;slave2:8485;slave3:8485/cluster1</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.cluster1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/apps/hadoop/tmp/journal</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence
shell(/bin/true)</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>10000</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
</configuration>
配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置yarn-site.xml文件
<configuration>
<!– Site specific YARN configurationproperties –>
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>rmcluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>master2</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master1:2181,master2:2181,slave1:2181,slave2:2181,slave3:2181</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value></property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
配置slaves文件
slave1
slave2
slave3
配置完毕,scp -p 发送主文件夹:
例如我的Hadoop,zookeeper,jdk全在apps文件夹下:发送到两台机器
scp -r /usr/apps master2:/usr/
scp -r /usr/apps slave1:/usr/
/etc/profile配置文件发送:
scp /etc/profile master2:/etc/
scp /etc/profile slave1:/etc/
发送完成修改zookeeper文件夹下的data下的myid文件
vim /usr/apps/zookeeper/data/myid
master1主机输入1
master2主机输入2
slave1主机输入3
再次提醒:关闭防火墙!
启动zookeeper集群:
启动命令:
每台服务器都执行: zkServer.sh start
查看集群状态命令:zkServer.sh status
master1节点执行格式化:hdfs zkfc -formatZK
journalnode共享存储:
所有(三台、五台、所有台)主机启动共享存储:hadoop-daemon.sh start journalnode
笔者注:
停止共享存储进程命令:每个节点执行 hadoop-daemon.sh stop journalnode 此项目中无需执行!!!
设置时钟同步:
所有主机:yum install -y ntp
master1主机:vim /etc/ntp.conf
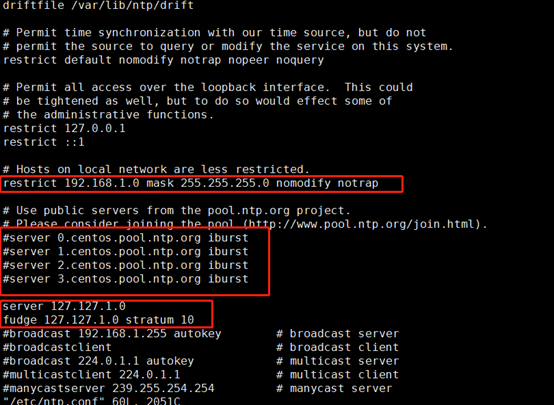
第一个红框:删除#注释标识
第二个红框:添加注释#
第三个红框:添加内容:server 127.127.1.0 和fudge 127.127.1.0 stratum 10
master1主机执行:
service ntpd start#开启ntpd时钟同步工具
chkconfig ntpd on#开启开机启动同步时间
service ntpd status#查看ntpd始终同步服务状态
master2主机和slave1主机执行:
service ntpd stop#停止时钟同步(无需)
chkconfig ntpd off#关闭时钟同步(无需)
ntpdate master1(和master1时间同步)
启动集群:
master1节点格式化activenamenode
hdfs namenode -format
master1和master2主机节点:
启动zookeeperfailovercontroller进程,出现故障自动切换
hadoop-daemon.sh start zkfc
master1主机节点启动activenamenode
hadoop-daemon.sh start namenode
master2主机节点同步数据:
hdfs namenode -bootstrapStandby
hadoop-daemon.sh start namenode
其他slave节点执行:(启动datanode节点)
hadoop-daemon.sh start datanode
搭建、启动完毕,验证可用性
验证ha故障自动转移:
浏览器打开:
http://master1节点IP:50070/ 为active状态
http://master2节点IP:50070/ 为standby状态
2)制造故障,杀掉namenode进程
Jps命令查看192.168.1.4节点namenode 进程号,并杀掉active节点进程
jps
kill -9 进程号
3)重新启动杀掉的namenode进程
在master1节点执行
hdfs namenode -bootstrapStandby
hadoop-daemon.sh start namenode
4)再访问浏览器
http://master1节点IP:50070/ 为standby状态
http://master2节点IP:50070/ 为active状态
如可行,即搭建成功
总结:
最初:
了解HA的含义
ZooKeeper:
配置/etc/hosts文件
配置zookeeper的conf下zoo.cfg文件
配置myid
Hadoop:
两个Java路径:hadoop-env.sh | yarn-env.sh
core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml等六个文件
如有问题请及时联系笔者【点击左下角任意图标即可联系】
![NTP时间服务器配置思路[详细版]](https://www.adminlog.cn/wp-content/themes/lolimeow/assets/images/rand/27.jpg?19E5KFcrqSB3JyluLDgMRiZeAbHfk4QhdO0zNwna2tT8XYVmx)

![Hadoop生态圈平台搭建[非高可用]](https://www.adminlog.cn/wp-content/themes/lolimeow/assets/images/rand/25.jpg?i1nIFyGETUP8xo3tBSNWluV4JRd9mXwf2Y5aAKZqveHgbDLjO)
