在Hadoop普通分布式的基础上搭建HA高可用,未搭建可以先戳链接查看:
高可用直接搭建也可参考:
文件/etc/profile和免密在之前文章中已做更改,故本文章不再重复操作撰写。
开始操作:
jps检查服务是否处于开启状态,若为开启状态执行关闭处理:(关闭为关闭所有节点的服务)
stop-all.sh (一键关闭)
stop-dfs.sh (关闭DFS服务)即关闭NameNode、SecondaryNameNode服务
stop-yarn.sh(关闭yarn服务)即关闭ResourceManager服务
因为需要正规一点,还需要关闭zookeeper服务(QuorumPeerMain):zkServer.sh stop(三台节点都要执行)
关闭服务后,修改/etc/hosts文件:vim /etc/hosts,将master
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.38.137 master1 192.168.38.138 master2 192.168.38.139 slave1
保存后发送(根据自己IP配置)scp发送,免密无需配置
特别提醒:以下所有文件内容都需要删除重写,未提及到的文件无需重写。
修改zookeeper/conf目录下的zoo.cfg文件:
vim /usr/apps/zookeeper/zookeeper-3.4.10/conf/zoo.cfg
要修改成和hosts相对应的名字:
server.1=master1:2888:3888 server.2=master2:2888:3888 server.3=slave1:2888:3888分发zoo.cfg文件:
scp /usr/apps/zookeeper/zookeeper-3.4.10/conf/zoo.cfg master2:/usr/apps/zookeeper/zookeeper-3.4.10/conf/
scp /usr/apps/zookeeper/zookeeper-3.4.10/conf/zoo.cfg slave1:/usr/apps/zookeeper/zookeeper-3.4.10/conf/
修改Hadoop的配置文件:
配置core-site.xml文件:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://cluster1</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/apps/hadoop/tmp</value> </property> <!--以下为添加内容--> <property> <name>ha.zookeeper.quorum</name> <value>master1:2181,master2:2181,slave1:2181</value> </property> </configuration>
配置hdfs-site.xml文件:
<configuration> <property> <name>dfs.replication</name> <!--下方的2改为1【因为是一台机器,如果有多台slave机器就按多台添加】--> <value>1</value> </property> <!--以下为添加内容--> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> <property> <name>dfs.nameservices</name> <value>cluster1</value> </property> <property> <name>dfs.ha.namenodes.cluster1</name> <value>master1,master2</value> </property> <property> <name>dfs.namenode.rpc-address.cluster1.master1</name> <value>master1:9000</value> </property> <property> <name>dfs.namenode.http-address.cluster1.master1</name> <value>master1:50070</value> </property> <property> <name>dfs.namenode.rpc-address.cluster1.master2</name> <value>master2:9000</value> </property> <property> <name>dfs.namenode.http-address.cluster1.master2</name> <value>master2:50070</value> </property> <property> <name>dfs.namenode.servicerpc-address.cluster.master1</name> <value>master1:53310</value> </property> <property> <name>dfs.namenode.servicerpc-address.cluster.master2</name> <value>master2:53310</value> </property> <property> <name>dfs.ha.automatic-failover.enabled.cluster1</name> <value>true</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <!--此处有多台机器需要修改下方的slave数字:8485--> <value>qjournal://master1:8485;master2:8485;slave1:8485/cluster1</value> </property> <property> <name>dfs.client.failover.proxy.provider.cluster1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/usr/apps/hadoop/tmp/journal</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence shell(/bin/true)</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>10000</value> </property> <property> <name>dfs.namenode.handler.count</name> <value>100</value> </property> </configuration>
配置mapred-site.xml:无需更改
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
配置yarn-site.xml文件:全部更改
<configuration> <!-- Site specific YARN configurationproperties --> <property> <name>yarn.resourcemanager.ha.id</name> <value>rm1</value> </property> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>rmcluster</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>master1</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>master2</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>master1:2181,master2:2181,slave1:2181</value> </property> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration>
配置slaves文件:删除slave2
slave1
分发配置文件:
scp -r /usr/apps/hadoop/hadoop-2.7.4/etc/hadoop master2:/usr/apps/hadoop/hadoop-2.7.4/etc/
scp -r /usr/apps/hadoop/hadoop-2.7.4/etc/hadoop slave1:/usr/apps/hadoop/hadoop-2.7.4/etc/
启动zookeeper集群:
提示:如果有多台机器,可先清除zookeeper的历史数据文件,重新分配leader和follows:删除cd /usr/apps/zookeeper/data/下的除myid外的所有数据即可重新分配领导者和随从者
提示:或者可以直接删除data目录下的所有文件后重新新建myid文件:rm-rf *(小写)
zkServer.sh start
master1节点执行格式化:
hdfs zkfc -formatZK
journalnode共享存储:
在五个节点上启动共享存储执行:
master1:
hadoop-daemon.sh start journalnode
master2:
hadoop-daemon.sh start journalnode
slave1:
hadoop-daemon.sh start journalnode
停止共享命令为:每个节点执行 hadoop-daemon.sh stop journalnode
设置时钟同步:
安装ntp时间同步工具:(三台主机都要安装)
yum -y install ntp
修改ntp时间同步工具配置文件:
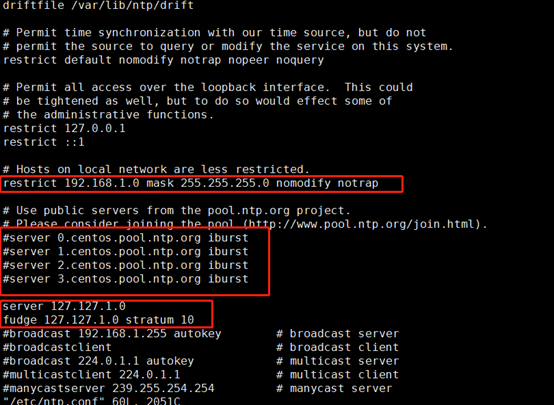
vim /etc/ntp.conf
第一个红框:删除#注释标识
第二个红框:添加注释#
第三个红框:添加内容:server 127.127.1.0 和fudge 127.127.1.0 stratum 10
server 127.127.1.0
fudge 127.127.1.0 stratum 10
master1节点执行:
service ntpd start
#开启时间同步服务
chkconfig ntpd on
#配置开机启动NTP时间同步
service ntpd status
#查看ntp的开启状态
其他节点执行:【是所有,包括其他master其他slave】
#注释参照上面
service ntpd stop
chkconfig ntpd off
ntpdate master1
出现:
[root@slave1 ~]# ntpdate master1 15 Nov 22:20:43 ntpdate[4393]: adjust time server 192.168.38.137 offset 0.000796 sec为成功(有读秒)
删除已启动过的节点数据(未启动过无需删除):
master1节点格式化activenamenode
hdfs namenode -format
slave1节点删除历史数据
rm -rf /usr/apps/hadoop/tmp/*
master1和master2启动zookeeperfailovercontroller进程,出现故障自动切换:
hadoop-daemon.sh start zkfc
master1节点启动activenamenode:
hadoop-daemon.sh start namenode
master2节点standbynamenode,同步数据:
hdfs namenode -bootstrapStandby
hadoop-daemon.sh start namenode
其他节点执行(启动datanode服务):
hadoop-daemon.sh start datanode
验证ha故障自动转移:
1)浏览器访问:
master1:50070为active状态
master2:50070/ 为standby状态
2)制造故障,杀掉namenode进程
Jps命令查看192.168.1.4节点namenode 进程号,并杀掉active节点进程
jps
kill -9 进程号
3)重新启动杀掉的namenode进程
在192.168.1.4执行
hdfs namenode -bootstrapStandby
hadoop-daemon.sh start namenode
4)再访问浏览器
master1:50070/ 为standby状态
master2:50070/ 为active状态
教程完毕经测试可执行,如未达到效果自行检查。
![NTP时间服务器配置思路[详细版]](https://www.adminlog.cn/wp-content/themes/lolimeow/assets/images/rand/17.jpg?RvmlO8bu0KoA2sYqULQn3fFCN54aMzIHihPBgGcXdrtyej6Jp)

![Hadoop生态圈平台搭建[非高可用]](https://www.adminlog.cn/wp-content/themes/lolimeow/assets/images/rand/16.jpg?YuZnlbdt80vSkEh6Czf5orWiF7qMpGOeBNXaTxyVUQ4PI2wcJ)
